MyHDL example: Avalon-ST Error Adapter
Another MyHDL experiment: the amazing Avalon-ST error adapter. I've mentioned this component before; here's a quick recap:
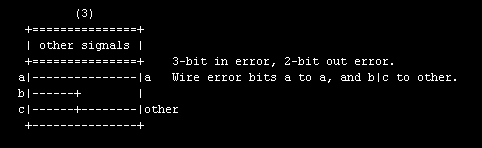
- The component has a single Avalon-ST sink and an single Avalon-ST source.
- "ordinary" inputs of the sink (e.g. roles data, valid) wire directly, combinationally, to outputs of the source. (Sink and source data widths must match.)
- "ordinary" inputs of the source (role ready) wire directly, combinationally, to outputs of the sink.
- The sink (and source) have an input (and output) of role error. Each individual sink and source error bit has an associated error type, which is a string. The sink and source error types need not match, nor must they have matching widths, thus some connection rules are required:
- matching (string match) error types are wired directly.
- if present, an output error bit of type "other" is driven from the logical OR of any otherwise non-matching input error bits
- any unmatched output error bits are driven with logical 0
As I showed in a previous article, avalon_st_error_adapter, this component, though simple to describe, is not so easy to generate. The Europa implementation turns out to be acceptable, by dint of some object overloading.
So - how does a MyHDL implementation of this component turn out?
Finding #1: It is possible!... but I certainly struggled with the implementation.
Two aspects of this component were difficult - not because it would be hard to code the logic in Python; rather, because it was hard to code the problem using the limited subset of Python which is convertible to Verilog.
- the wiring-together of matching error bits, wherever they appeared in the error ports (component permute from the previous article was this problem, in disguise):
In MyHDL, I created a mapping tuple, outputMapping, whose element of index 'i' gave the index of the input error signal which drove output error bit i. Then I loop over all matching output bits, assign the proper index bit to a variable (which becomes a signal in Verilog), and drive the output from the given input bit, something like this:
# (j is large enough to hold any index into intermediate.) j = intbv(0, min=0, max=2 + len(i_err)) for i in range(len(outputMapping)): j[:] = outputMapping[i] o_err.next[i] = intermediate[int(j)]
Notice that I use an intermediate signal, rather than assigning directly from the input error signal. The intermediate signal is 2 bits wider than the input error signal. One "extra" bit is driven with 0 (for otherwise undriven outputs); the other is driven with the logical OR of any "other" input bits. This way, I know the index value from which to drive every output error bit, whether it's a direct-map bit, an "other" bit or an output which must be driven with 0.
- forming the logical OR of all otherwise unconnected error inputs to drive the 'other' error output. The way I solved the puzzle was to create another tuple, otherList, containing indices of input error bits which are to be OR'ed into the output "other" bit. In another for loop, I loop over all the elements of the tuple, iteratively OR'ing in each bit into the correct bit of the intermediate signal, like this:
# (k is large enough to hold any index into intermediate.) k = intbv(0, min=0, max=2 + len(i_err)) for i in range(len(otherList)): k[:] = otherList[i] intermediate[otherIndex] = \ intermediate[otherIndex] | intermediate[int(k)]
The implementation code looks very very unlike the conceptual picture in one's brain - it should be more like straight bit assignments, and an OR gate. The violent disagreement between concept and implementation is the sort of thing that makes my spider-sense tingle.
Finding #2: Unit testing is swell.
My design flow here was to add a feature, add a test for it, add another feature, add another test, ... This worked great: I found lots of bugs quickly as I went, and the need to write tests forced me to carefully consider interface/API issues.
Here's what one of my tests looks like: it tests the function of a the simplest possible error adapter, with a single input and output error bit of matching type:
def testA(self):
"""
Simple case: data, valid, ready, one-bit matching input and output error.
(Arguably this shouldn't be a valid error adapter - there's nothing to
adapt! Philosophical issue whether or not this should be supported. I'm
going to allow it, because to make a special case of it to exclude it
would be more work.)
"""
# Direct mapping.
def error_map(i_err):
return i_err
self.doATest( \
"testA", \
8, \
{ 'o_err': { 'a' : 0, }, 'i_err': { 'a' : 0, }, }, \
error_map = error_map, \
)
In this test I define the mapping from input error to output error, the data width, and the hash which defines the error bit mapping. Utility routines do the rest of the work of creating the actual adapter, running the simulation, verifying the outputs vs. the inputs, and running toVerilog on the adapter. Other tests have a similar framework - only the error mapping routine, the data width and the parameterization hash are varied. See test_avalon_st_error_adapter.py for the rest of the tests, and the definition of test utility routine doATest.
Finding #3: That Verilog is nigh-unreadable!
Perhaps as a natural result of the fact that the implementation relies on special MyHDL "tricks", the Verilog output appears to have been written by an evil genius. For example, if the input and output error bits are defined as follows:
{
'o_err': { 'nomatch' : 0, 'other' : 1, 'a' : 2, 'c' : 3, },
'i_err': { 'a' : 1, 'b' : 2, 'c' : 0, 'd' : 3, 'e' : 4, 'f' : 5, },
},
you might hope that the output error bit assignment would look something like this:
assign other = i_err[5] | i_err[4] | i_err[3] | i_err[2];
assign o_err = {i_err[0], i_err[1], other, 1'b0};
rather than this:
always @(i_err) begin: _testG_mapOutputErrorBits
integer i;
reg [3-1:0] k;
reg [8-1:0] intermediate;
reg [3-1:0] j;
intermediate = {1'h0, 1'h0, i_err};
k = 0;
for (i=0; i<4; i=i+1) begin
// synthesis parallel_case full_case
case (i)
0: k = 2;
1: k = 3;
2: k = 4;
default: k = 5;
endcase
intermediate[6] = (intermediate[6] | intermediate[k]);
end
j = 0;
for (i=0; i<4; i=i+1) begin
// synthesis parallel_case full_case
case (i)
0: j = 7;
1: j = 6;
2: j = 1;
default: j = 0;
endcase
o_err[i] <= intermediate[j];
end
end
So it goes. The illegibility of the Verilog output may not matter so much in practice, if 1) the unit test facilities lead to well-verified logic, so that the Verilog doesn't need to be studied for bugs (when was the last time you looked for bugs in an assembler listing of your C code?), and 2) the toVerilog function is reliable.
I think that'll be it for now. As usual, I include a full archive of the code: